$ cat blog/neo4j-first-steps.md
First Sketches -- It's a Graph!
Originally published on speedydev.pl in 2017 as part of the Daj Się Poznać blogging contest. Republished here for archival purposes.
Back to kindergarten, basically. But this feature is absolutely mind-blowing — someone deserves $1M for it.
If it weren’t for the visualization, I’d probably have spent way more time banging my head against SQL queries that look like spreadsheet formulas. My graph theory knowledge is roughly “two lines on an exam paper” level — but after a talk by Szymon Warda (@maklipsa) at rg-dev Rzeszów, something clicked.
The lightbulb moment hit a couple days later: “This is literally a connection map.” And then: “Wait, this thing eats JOIN chains for breakfast, has its own query language, and you can traverse it without nesting if-statements five levels deep.”
Enter Neo4j: https://neo4j.com/
The visualization alone is worth the install. Just typing MATCH (s) RETURN s and watching things appear on screen is genuinely exciting. The only danger: Chrome RAM.
Importing the Railway Data
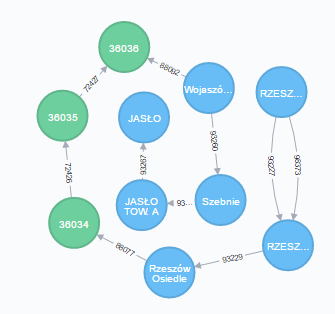
The dataset: railway segments and stops (Points) from a SQL database.
-- First: always run this. Best script because you run it last.
MATCH (n) DETACH DELETE n;Import segments:
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:///Segment.csv" AS row
CREATE (:Segment {
lineNo: toInt(row.lineNo),
speedLimit: toInt(row.speedLimit),
relationSort: toInt(row.relationSort),
kmFrom: toFloat(row.kmFrom),
kmTo: toFloat(row.kmTo)
});Import points (stops):
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:///point.csv" AS row
CREATE (:Point {name: row.nazwa});Connect segments along their line:
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:///tracks2.csv" AS row
MATCH (sta:Segment {lineNo: toInt(row.lineNo), relationSort: toInt(row.relationSort)})
MATCH (stc:Segment {lineNo: sta.lineNo, relationSort: (sta.relationSort + 1)})
MERGE (sta)-[:Continue]-(stc);Connecting Points to Segments by km position (ran this script ~30 times until it worked):
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM "file:///pointLocation.csv" AS row
MATCH (p:Point {name: row.nazwa})
MATCH (stc:Segment {lineNo: toInt(row.nr_lini)})
WHERE toInt(row.km_os) >= toInt(stc.kmFrom)
AND (toInt(stc.kmTo) > toInt(row.km_os) OR toInt(row.km_os) = toInt(stc.kmTo))
MERGE (p)-[:Stay {km: toFloat(row.km_os), lineNo: toInt(row.nr_lini)}]-(stc);Finding the Shortest Path
Neo4j gives you this for free:
MATCH (s:Point), (e:Point),
p = shortestPath((s)-[*]-(e))
WHERE s.name = 'JASŁO' AND e.name = 'RZESZÓW'
RETURN pThis returns the shortest path by number of relationships, not by actual distance. Fixing that is the next challenge.
(Post published on International Women’s Day — cheers!)